At ufirst we build AI-powered solutions while exploring what’s actually functional in this ever-shifting landscape. Our focus is utility and reliability, so we invest heavily in prototypes and tech demos before shipping anything to clients. Most explorations end up gathering dust in forgotten GitHub repos, yet sometimes we stumble upon findings worth sharing: patterns we believe will set standards for future implementations.
This article tells the story of one such exploration. It started almost as an experiment to waste some time, and unexpectedly led me to build a Knowledge Graph-based RAG system while trying to solve another, completely different and rather specific problem: constructing a timeline of events surrounding people, places, and evidence from a large corpus of Italian legal documents related to the Garlasco Murder Case—one of Italy’s most controversial criminal cases, still generating developments 17 years later.
The interesting part wasn’t the timeline itself. It was discovering that building the Knowledge Graph properly made retrieval, visualization, and a plethora of other possibilities a natural consequence. The graph didn’t just enable RAG—it made RAG almost trivial, among many other possible solutions.
Here I intend to discuss this journey in a less technical, more conversational way—accessible regardless of your technical background. A more implementation-focused article may follow.
My initial goal was to derive structured data from a large corpus of legal documents (humungous PDFs full of Italian court jargon) and feed it to a visual timeline. Each section should map to an event in time, detailing all relevant entities—People, Places, Evidence, Documents. I wanted source traceability so users could verify claims and dive deeper, and I wanted extensibility: adding new documents should enrich the timeline without reprocessing everything.
To do this, I needed to go beyond simple summarization. I needed to map documents to conceptual entities, track how those entities evolved across documents, and enable both information retrieval and artifact generation.
Given these constraints, the shape of the solution was clear. Tracking people, events, rulings, and dates—and their connections over time—is inherently a graph problem. “Ok, I might need some named entity recognition for people and events, tie dates to events and people, then track where entity X appears across documents.”
After some research, I came to the conclusion that the best approach was to define a proper taxonomy of the entities I wanted to represent and build a knowledge graph. If it worked (and it did), the “timeline” would just be the result of querying Event nodes and sorting by date.
Knowledge graphs aren’t new—they’ve been around for decades, powering everything from Google’s search results to enterprise data integration. The core idea is simple: represent information as a network of entities (nodes) connected by relationships (edges). A Person node connects to an Event node via an INVOLVED_IN relationship. That Event connects to a Place via LOCATED_AT. Each node can carry properties: names, dates, roles, descriptions. Instead of flattening everything into rows and columns, you preserve the natural structure of how things relate.
The challenge is that knowledge graphs have traditionally been a pain to build and maintain. You need clean data, consistent schemas, and a lot of manual curation. For most use cases, the juice wasn’t worth the squeeze—but since I love to make my life difficult, and I always wanted to play around with knowledge graphs, I decided to give it a go.
LLMs can now extract entities and relationships from unstructured text at scale, dramatically lowering the construction cost. And once you have a graph, you can combine structured traversal with semantic search—a hybrid more powerful than either alone. Microsoft Research has been exploring this with GraphRAG; Neo4j has built native vector search into their graph database; frameworks like LangChain and LlamaIndex integrate with these technologies by default. The ecosystem momentum reassured me I wasn’t completely off the beaten path.
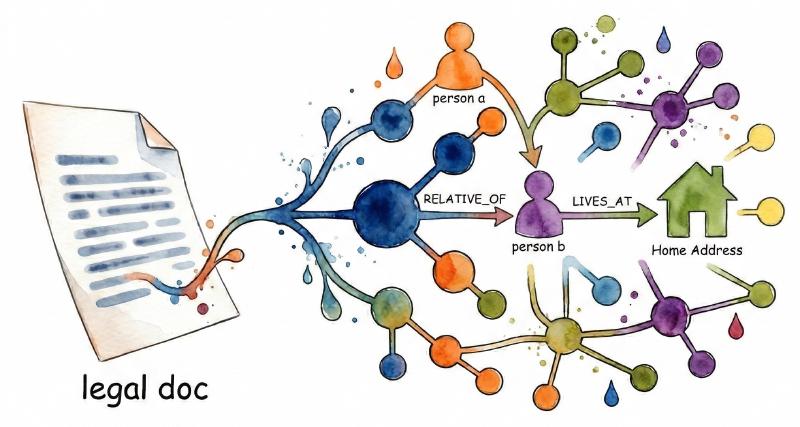
For my use case, I needed a specific structure: entities like Person, Event, Place, and Evidence, connected by relationships like INVOLVED_IN or RELATIVE_OF. The structure that emerged—and the architectural insight that made everything else possible—I’ll explain when we get to building it.
The first challenge was getting text out of the documents themselves. Italian court filings aren’t exactly machine-friendly: scanned PDFs, inconsistent formatting, dense legal prose.
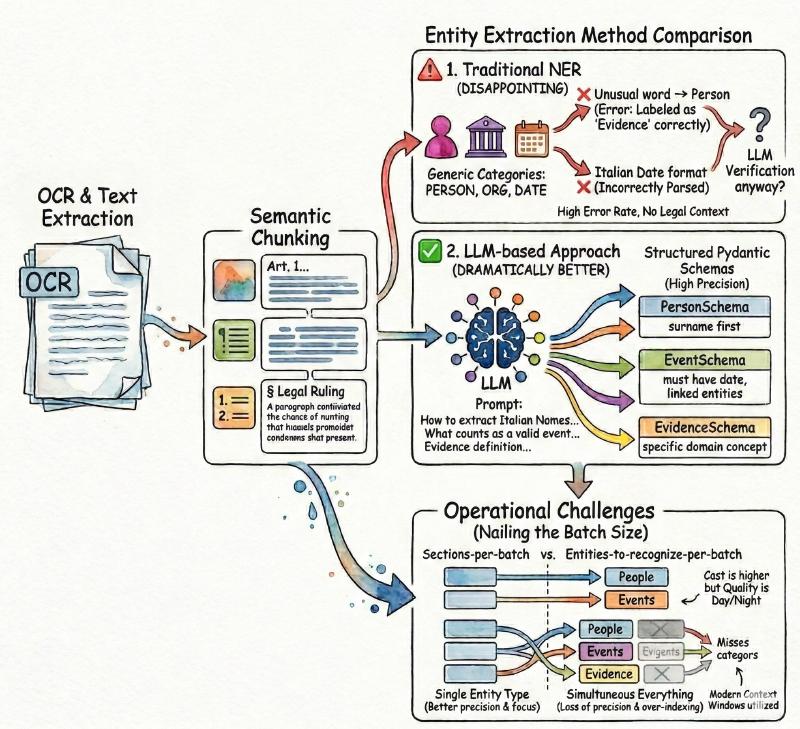
I set up a pipeline starting with OCR and text extraction, then semantic chunking—breaking documents into meaningful sections rather than arbitrary character counts. Getting the chunking right matters: too small and you lose context; too large and the extraction model struggles to focus. I settled on a hybrid approach that respects document structure (headers, paragraphs, numbered lists) while keeping sections digestible for the LLM, configurable per document.
With clean, chunked text in hand, the next step was entity extraction. My first instinct was traditional NER tools—I tried SpaCy, which has solid Italian language models. But the results were disappointing. Standard NER recognizes generic categories (PERSON, ORG, DATE), not domain-specific concepts like “evidence” or “legal ruling.” Worse, it mislabeled constantly: unusual words tagged as Person, dates parsed incorrectly from Italian formats. I’d need an LLM to verify and correct anyway, so why not cut out the middleman?
The LLM-based approach worked dramatically better. I feed each document section to the model with detailed guidance—not just “extract people,” but how Italian names work, what counts as a valid event, what distinguishes a “place” from an address. The model returns structured entities matching my Pydantic schemas with remarkably high precision. The cost is higher than NER, but the quality difference is night and day, with plenty of room for optimization through private models or fine-tuning.
The biggest hurdle was nailing the right batch size. Extracting one entity type at a time works better than asking for everything at once, while modern context windows let you provide many document sections per batch without losing precision. When I prompted the model to extract people, events, places, and evidence simultaneously, it would often miss one category entirely while over-indexing another—a consistent pattern across multiple experiments.
One neat trick: I map each extracted entity to a list of facts—short summaries of how and where that entity appears in the document. A Person might have facts like “mentioned as the defendant in the 2007 murder trial” and “testified during the appeal proceedings.” These facts reference the specific document sections they came from, creating a three-level hierarchy: Entity → Fact → Section. This enables versatile querying: concept-level (find all events involving this person), fact-level (retrieve supporting context), and source-level (drill down to actual text)—structured queries with full traceability. The hierarchy emerged organically from the extraction workflow, but turned out to be the most valuable architectural decision in the whole project.
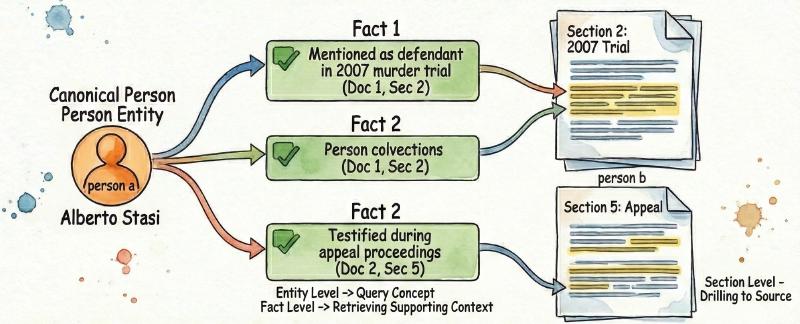
Deduplication was the next hurdle. Legal documents don’t use consistent naming—the same person might appear as “Alberto Stasi,” “Stasi,” “l’imputato” (the defendant), or “il giovane” (the young man). I needed one canonical representation per entity, no matter how many references. The solution: a two-stage approach. First, field comparisons catch obvious duplicates—same name and surname, same event title and date. For ambiguous cases, I route to an LLM with all the facts for both candidates: “Given these two Person entities, are they the same individual?” The model reasons about context in ways string matching never could.
Relationship extraction is where things get genuinely hard. The combinatorial problem is daunting: every person could relate to every event, every event to every place. You can’t compare everything against everything—the token costs alone would be prohibitive.
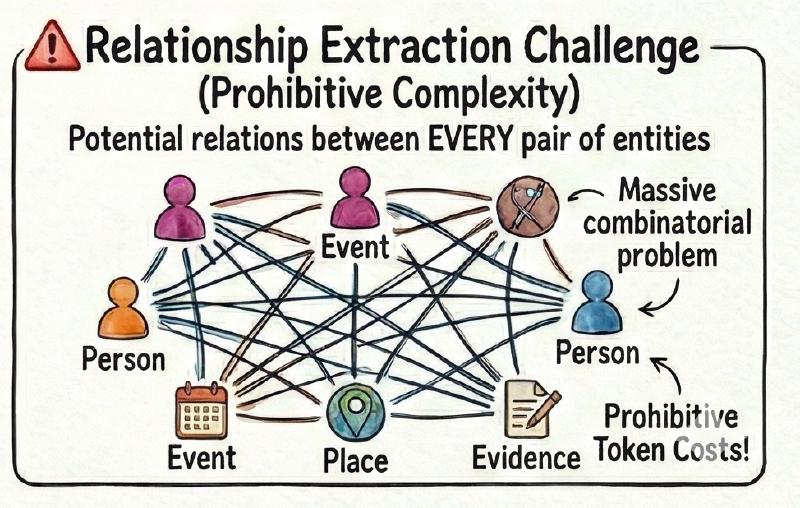
My approach uses relationship “bundles”: predefined groups that make sense together. Social relationships (RELATIVE_OF, KNOWS) form one bundle, only between people. Factual relationships (INVOLVED_IN, LOCATED_AT) form another, connecting people to events and places. For each bundle, the LLM receives all relevant entities and their facts, identifying which relationships actually exist.
I’ll be honest: entity extraction works well; relationship extraction can be improved. My optimizer brain knows there’s a better way than brute-forcing entities against an LLM, and I’ve begun exploring solutions like Neo4j’s graph data science library to detect clusters of semantically related entities. But even with imperfect relationships, the graph is robust. And the entities themselves, with their facts and source links, already enable powerful queries.
That’s for me the funniest part: RAG wasn’t even the original goal. I built the knowledge graph for the timeline—that was the whole point. But once the graph existed, with entities linked to facts linked to source sections, adding RAG capabilities was almost trivial. All it took me, in about 30 minutes of coding, was to wire up a Pydantic AI agent with a handful of tools to navigate the graph, wrote a prompt that was honestly pretty rough around the edges, and the results exceeded every expectation I had. The graph had already done the hard work of organizing information; the agent just needed to navigate it.
This accidental discovery got me thinking about why traditional RAG approaches struggle with certain problems, and why the graph-based alternative felt so much more natural.
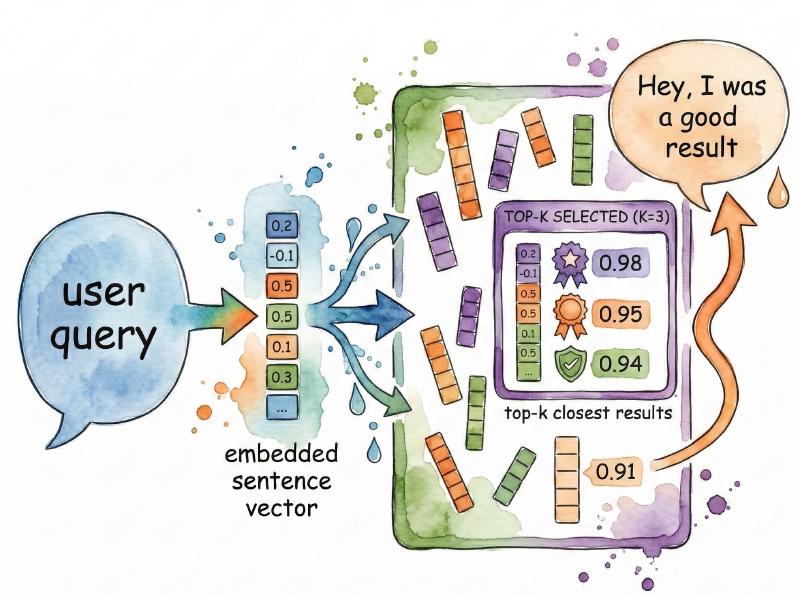
The bare, “naive”, RAG pattern is straightforward: take a user query, convert it to an embedding, find document chunks with similar embeddings, stuff those chunks into an LLM’s context window, and generate a response. It works remarkably well for many use cases. But there’s a fundamental limitation baked into the approach: relevance is measured geometrically, not semantically.
When you retrieve by embedding similarity, you get chunks that look like the query in vector space. That’s not the same as chunks that actually answer it. A question about “the defendant’s alibi” might retrieve passages mentioning “defendant” and “alibi” separately, but miss the paragraph that actually explains the alibi—because it uses different words. The retrieved chunks can also be homogeneous: five variations of the same information instead of the diverse context you need.
The top-k cutoff makes this worse. If relevant information is in the 11th most similar chunk and you’re retrieving the top 10, you’ll never see it. Tracking relationships over time—“how did the court’s position on DNA evidence evolve across appeals?"—isn’t a similarity search problem at all. It’s a structural query requiring understanding of which entities connect to which events in which order.
Research confirms these limitations. Microsoft’s GraphRAG paper found that vector RAG struggles with “sensemaking queries”—questions requiring global understanding rather than point lookups. The KG2RAG paper documented that semantically retrieved chunks “can be homogeneous and redundant, failing to provide intrinsic relationships among chunks.”
To be fair: production RAG systems aren’t this naive. There’s a whole toolkit of optimizations—reranking, query expansion, hybrid search, iterative retrieval, LLM-based refinement. These genuinely help, and for many applications they’re sufficient. But they’re still fundamentally patching a geometric retrieval system to behave more semantically. Knowledge Graph-based RAG addresses the root problem: structure information so the right context is naturally accessible. And with graph databases like Neo4j supporting vector embeddings, you still get semantic search when you need it. It’s versatile, domain-agnostic once you define your taxonomy, and addresses the root problem rather than its symptoms.
I wasn’t the first to notice this gap. The idea of combining knowledge graphs with RAG has been gaining momentum, and Microsoft Research’s GraphRAG approach deserves mention. Their system extracts entities, uses Leiden community detection to cluster related entities, generates hierarchical summaries, and answers queries by synthesizing partial answers across the hierarchy. On comprehensiveness metrics, they report 72-83% win rates over vector RAG—impressive work, especially for global questions like “What are the main themes in this dataset?”
Neo4j, meanwhile, has built native vector search directly into their graph database, enabling hybrid queries that combine structured traversal with semantic similarity. The ecosystem is clearly moving toward this kind of integration.
When I tested Microsoft’s approach out of the box, I ran into friction: auto-inferred entities yielded duplicates, inconsistent naming, and a knowledge base only the AI could navigate. Now, GraphRAG does support configuration for predetermined entity types—you’re not locked into auto-inference. But by the time I understood the framework deeply enough to customize it, I’d already started building my own pipeline. We developers love to preach “don’t reinvent the wheel” while quietly crafting artisanal wheels in our garages. In my defense, rolling my own gave me exactly the control I wanted: a graph optimized not just for retrieval, but for structured workflows like building a timeline or tracking entity evolution across documents.
My approach goes the other direction: define your entity types upfront, extract to that schema, and accept that you might miss some connections in exchange for control and predictability.
The tradeoffs are real. A predetermined taxonomy means deciding in advance what matters, which requires domain knowledge and might cause you to overlook unexpected patterns. Auto-inference can surface things you didn’t know to look for. But for my use case—and I suspect for most production applications—the benefits are substantial.
First, you can actually query the graph programmatically. Want all events involving a specific person, sorted by date? That’s a simple Cypher query when you know Event and Person are node types with predictable properties. With auto-inferred entities, you’re back to hoping the LLM figures out what you mean.
Second, debugging becomes tractable. When extraction goes wrong, you know which entity type misbehaved and can adjust its description. With auto-inference, problems are diffuse and hard to diagnose.
Third—the real payoff—predetermined entities act like model objects in a traditional application. They’re not just retrieval fodder; they’re structured data you can build features around. The timeline? Sort Event nodes by date. A relationship graph? Query KNOWS and RELATIVE_OF edges. Automated triage? Filter by label. The graph enables workflows beyond question-answering.
Once you have a well-structured knowledge graph, retrieval stops being a search problem and becomes a navigation problem. The agent doesn’t guess which chunks might be relevant; it traverses from a known entity to its facts to related entities, building context deliberately rather than probabilistically.
The Entity → Fact → Section hierarchy makes this work. An agent answering “What role did Alberto Stasi play in the initial investigation?” doesn’t search for similar text. It finds the Person entity, retrieves his facts, identifies which relate to investigative events, pulls those Event entities, and follows the chain to source sections. Every step is traceable. Every piece of context is there for a reason.
This isn’t just more accurate—it’s more transparent. When the agent cites a source, you can verify exactly why it was included. The reasoning path through the graph is explicit, not hidden inside embedding similarity scores.
The implementation is surprisingly simple. The agent has a small set of tools: search entities by name or description, retrieve facts for an entity, find related entities through specific relationship types, and fetch original source text for any fact. No text-to-Cypher translation, no complex query language exposed to the LLM. I considered letting the agent write arbitrary graph queries, but it’s error-prone—hallucinated property names, misremembered relationship directions, invalid Cypher. Simple, purpose-built tools turned out to be far more reliable.
The agent plans its own traversal. Given a question, it decides which entities to search first, what relationships to explore, when it has enough context. I cap iterations to avoid loops, but in practice the agent converges quickly—the graph’s structure guides it naturally toward relevant information.
The RAG results were satisfying, but the bigger realization was that entities in the graph aren’t just retrieval fodder—they’re model objects. They behave like database rows with semantic context attached. You can run traditional data-driven workflows on them: filter by type, aggregate by property, trigger actions based on entity state—all while keeping semantic search and LLM-powered reasoning.
This opens possibilities pure RAG can’t touch. A tech support system built on a knowledge graph of products, known issues, and troubleshooting steps: the agent navigates from symptoms to matching issues to resolutions, building responses from structured relationships rather than hoping the right paragraphs appear in top-k. Or automated triage: incoming documents parsed, entities extracted, routed based on what the graph already knows.
The pattern is domain-agnostic. Legal documents were my test case, but it applies to healthcare records, supply chain logistics, financial compliance—anywhere relationships matter and “find similar text” isn’t enough. Define your taxonomy. Build the graph. Get navigation, retrieval, and data-driven workflows as natural consequences.
I’ve started generalizing this into a reusable framework—entity types defined through descriptors, extraction and deduplication as composable operations, the graph database abstracted behind ports. It’s not ready for public release, but it’s getting closer.
The insight I keep coming back to isn’t “use a knowledge graph.” It’s simpler: structure your text around concepts—around what actually matters to your domain. Once you do, retrieval becomes navigation with clear paths. Vector databases with careful metadata might achieve something similar. The point is that semantic similarity alone isn’t enough when you need to reason about structure.
Whether you’re building a legal timeline, a tech support agent, or something I haven’t imagined: understand your domain, define your entities, connect them to your source material, and let the structure do the heavy lifting. The LLM becomes a navigator rather than a guesser. That’s the shift.
